An active second line of inquiry.
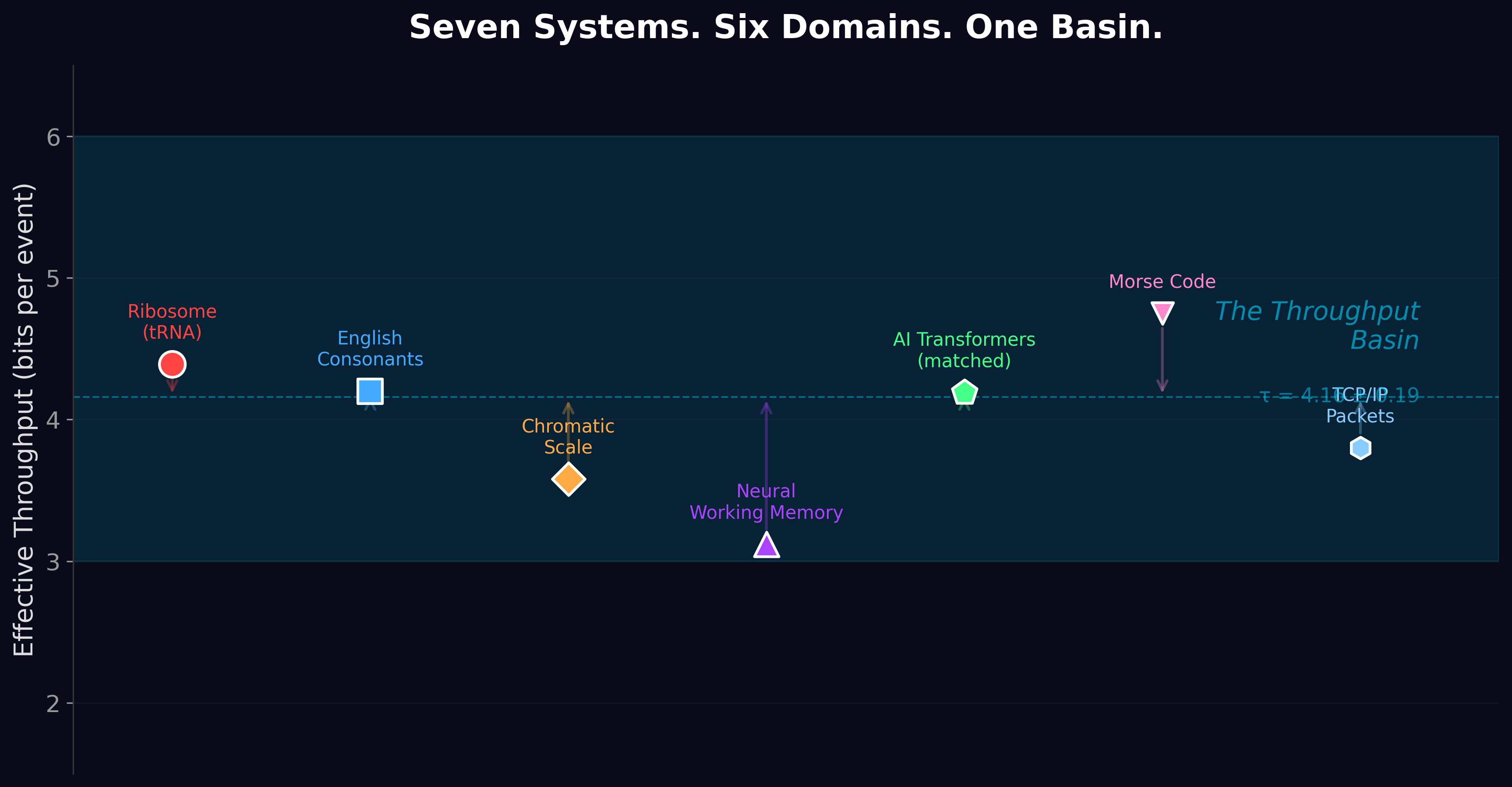
Non-equilibrium thermodynamic bounds in analog physical systems — the same Clausius-inequality lens that drives Track 1’s thermodynamic argument, applied to a different substrate. Seven papers now in the field: a narrow falsifiable laboratory prediction, the framework paper introducing the static escrow postulate, a methodology case study, a direct lattice-QFT test, a translation of standard GR results into the escrow vocabulary, an 𝒩esc recipe spanning three gravitational regimes, and a Compton-scale Hilbert-space corollary.
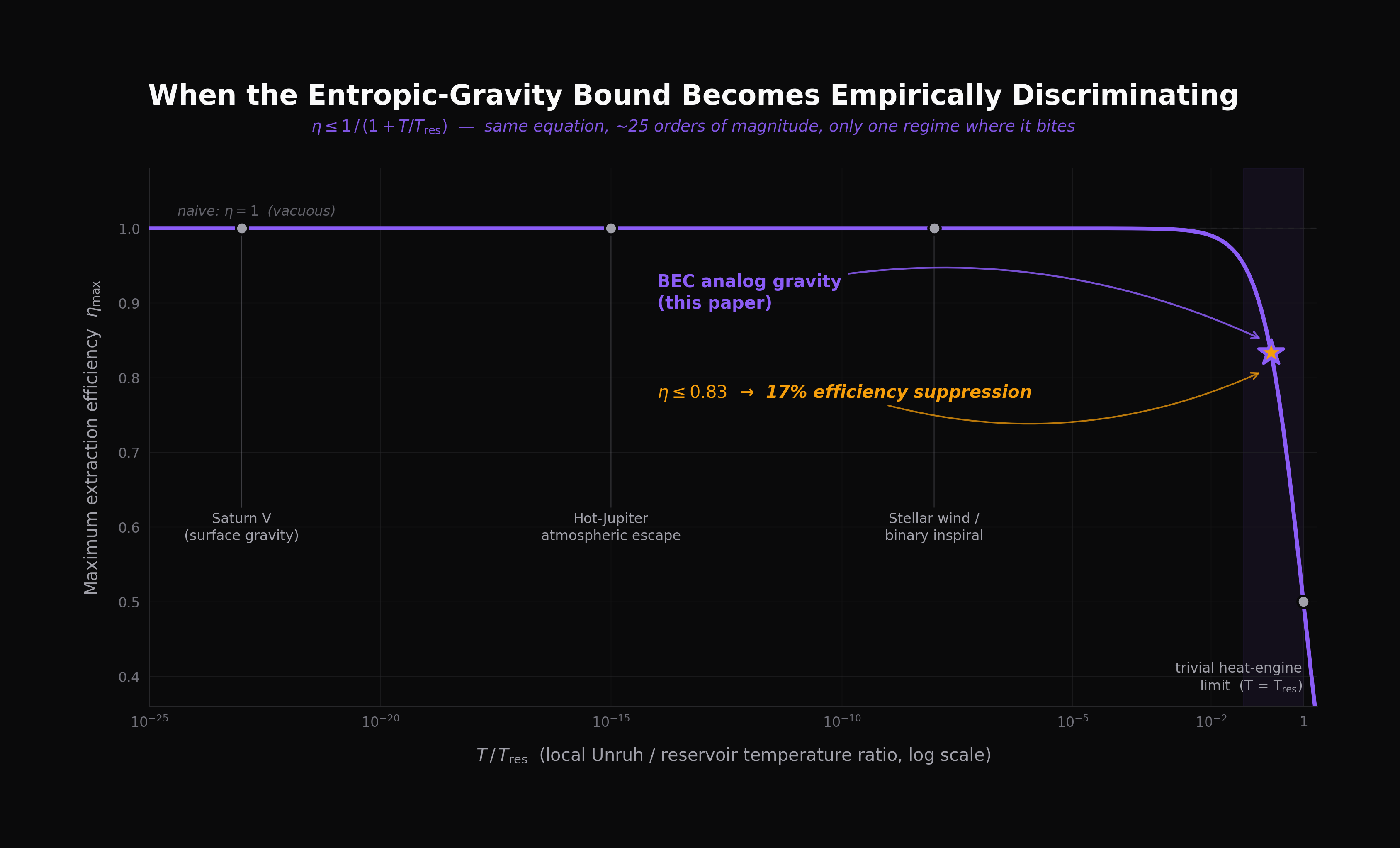
The Phonon Bound: A Non-Equilibrium Efficiency Bound for Phonon Extraction in BEC Analog Gravity
Verlinde’s entropic-gravity construction yields, under one explicit thermodynamic assumption, the bound η ≤ 1/(1 + T/Tres). In every astrophysical setting the ratio is essentially zero and the bound is vacuous. In Bose–Einstein condensate analog gravity the ratio is ≈ 0.2 and the bound predicts a 17% efficiency suppression distinguishable from naive energetic accounting and from mundane experimental losses by its specific functional form. The load-bearing assumption is tested across five independent QuTiP Lindblad simulations.
Gravitational Entropy Escrow — or, Why Does Gravity Pull?
A reframing of gravity as the universe’s collection agency for an entropy debt — the universe attracts because the books want to balance. The same picture explains why gravity always pulls and never pushes, why you can’t shield it, why a falling elevator feels like nothing, why black holes are entropy maxed out into geometry, and why galaxies stop obeying Newton at exactly the acceleration scale set by the “chill” of empty space. A five-case test on the most distant galaxies the Genzel team has measured supports the framework’s commitment to a constant cosmic floor over alternatives. The cluster-cores problem is flagged honestly as a real difficulty the picture can’t yet dissolve.
The C8 Clarification Note — or, the AI Proposed a New Equation. It Was From 1981.
A short companion to Paper 11. Multiple AI systems independently proposed a candidate covariant extension — a beautiful-looking entropy-current equation that reproduced both Bekenstein–Hawking and Gibbons–Hawking entropies exactly. We show it’s algebraically identical to a 1981 Bekenstein result wearing a costume. The methodology section — how three of four AI systems were confidently wrong about a unit convention, and how reality-checks against published Planck 2018 values resolved it — turns out to be the more general contribution.
The Lattice QFT Test — Half a Falsification.
Supplement to Paper 11. The framework’s static identification Sesc = |Ugrav|/TUnruh is tested directly against lattice quantum field theory across three independent entropy measures. The literal bipartition-entropy reading fails by 1056 orders of magnitude across a 295-point parameter grid in 1+1D, and is bounded below 10−3 in 3+1D. The modular Hamiltonian reading partially survives in 1+1D: the Bisognano–Wichmann linear asymptote ΔK ∝ d1 is approximately recovered in a small-d1 window with prefactor ≈ 1/30. The previously-published “ΔK ∝ L0.7” sublinear fit is corrected here to a regime-dependent characterization — the 0.7 was a fitting artifact across a smooth crossover. The framework’s horizon-limit recoveries (Bekenstein–Hawking via surface gravity) are independent of these flat-space tests; what fails is the load-bearing static identification, what survives is a structurally-correct modular content with calculable suppression as the open question.
Spacetime as Escrow Bookkeeping.
A translation paper, not a derivation paper. Four standard results of general relativity — gravitational time dilation, the Tolman temperature law, the Bekenstein–Hawking entropy formula, and Jacobson’s (1995) thermodynamic derivation of Einstein’s field equations — are re-read through the escrow vocabulary. The single thermodynamic ratio Sesc = |Ugrav|/TU lets all four be expressed as faces of one identity. None of the underlying physics is modified. Equation (8) isolates 2πr/λC as the test-mass leg’s dimensionless organizing variable; equations (17)–(18) show the postulate’s Schwarzschild entropy equals the Bekenstein–Hawking value to all displayed digits without a fudge factor. The paper is explicit (§V.G–H) that the “single object” description is partly notational: |Ugrav| takes regime-specific forms across the four legs, and TU is used with two related-but-distinct conventions. The 1/30 prefactor from Paper 13 is reframed here as a specific calculational question about how lattice-regulated free QFT approaches its continuum Bisognano–Wichmann limit — not a free-floating empirical curiosity. Includes pre-registered retraction commitments for five falsification conditions.
The 𝒩esc Recipe — One Function, Three Regimes.
Continuation of Paper 14. Formalizes the 𝒩esc notation as a two-argument function 𝒩esc(E, L) ≡ 2πEL/(ℏc), then observes that the static escrow recipe Sesc = |U|/T evaluates to this Bekenstein-bound saturation form in three qualitatively distinct gravitational regimes: test mass in Schwarzschild, Bekenstein–Hawking entropy via Smarr, and a localized perturbation in a Rindler wedge (identified with Casini’s QFT bound). The function is Bekenstein’s; the recipe is the framework’s. The Smarr partition lives in the recipe, not the function arguments. First-principles 1+1D and 3+1D lattice runs anchor the Rindler-wedge sector: boost-generator BW identification at 0.087% mean accuracy across 10 parameter combinations (Table 3); Casini–BW inequality verified within max 5.4% saturation at the Compton scale. Theorem 1 is conditional, properly stated, and properly proved — the framework’s claim is conditional on BW, Casini, and moment-positivity. Five pre-registered retractions.
The Compton Corollary — A Hilbert-Space Ceiling and an E8 Coincidence.
Short empirical observation paper. Evaluating Bekenstein’s bound at the reduced Compton wavelength λ̄C = ℏ/(mc) of a massive elementary particle gives a value independent of mass: Smax = 2π kB, equivalently D ≤ e2π ≈ 535.49. Universal ceiling on the dimension of a particle’s internal Hilbert space at its own Compton scale. The numerical coincidence: the five Cartan-exceptional simple Lie algebras (G2, F4, E6, E7, E8) have adjoint dimensions whose natural one-particle counts 2 dim(adj G) climb monotonically toward this ceiling, with E8 sitting at 92.6% linearly / 98.8% in log2, and the Cartan classification terminates with E8. Uses 𝒩esc notation only; the escrow recipe of Papers 11/14/15 is not invoked. The paper is explicit about the domain mismatch (the 2 dim(adj G) count belongs to massless gauge bosons, which have no Compton wavelength) and gives the coincidence reading the most defensible weight.
A note on scope. Seven papers in, Track 2 now spans the full spectrum: a narrow falsifiable laboratory prediction (Paper 10), the framework paper introducing the static escrow postulate (Paper 11), a methodology case study on a candidate extension that turned out to be a 1981 result in disguise (Paper 12), a direct lattice-QFT test of the framework’s load-bearing identification (Paper 13), a conceptual translation showing that four standard GR results can be re-read as faces of one thermodynamic identity (Paper 14), a cross-regime observation that the same recipe |U|/T produces the Bekenstein-bound saturation form 𝒩esc(E, L) = 2πEL/(ℏc) in three qualitatively distinct gravitational regimes — with first-principles lattice verification of the Rindler-wedge inequality at 0.087% mean accuracy on the BW identification (Paper 15), and a short corollary observation recording the mass-independent D ≤ e2π ceiling at the Compton scale and the E8 coincidence at 92.6% of that ceiling (Paper 16). We are still not promising a roadmap. Sometimes the honest contribution is “here’s what we tried, here’s why the literal version doesn’t work, here’s what survives anyway, here’s how it connects to fifty years of thermodynamic-gravity literature we hadn’t made the connection to explicit yet.”