The bird's-eye view of the whole first act — nine papers, condensed for anyone, no math required. Each chapter has its own fuller story linked along the way. Grab a coffee.
Let me tell you a fact that ought to keep you up at night, just a little.
Deep in your cells, a molecular machine reads genetic instructions and squeezes out a certain small handful of information per step. In your ears, the machinery that turns air-wiggles into words extracts a suspiciously similar handful per step. And when a modern AI reads a sentence, it too pulls out roughly that same small handful per chunk. Three machines — one made of proteins and polished by three and a half billion years of evolution, one made of neurons, one made of silicon and slapped together by engineers last Tuesday — and they all seem to fill up at nearly the same waterline.
That could be a coincidence. The whole first act of the Windstorm Institute has been one long, stubborn attempt to find out whether it is. The answer, after nine papers and a mountain of experiments — and, honestly, a few faceplants we'll show you along the way — is that the pattern is real and it's stubborn. Whether it rises to a law of nature is the question these nine papers chase, and our best answer is: probably, but we'll show you exactly where the case is still open. The universe may run a speed limit on thought. Here's how we chased it down.
Chapter 1: Why Life Spells Everything in 64 Letters
It starts, as these things do, with DNA. Every living thing writes itself in a four-letter chemical alphabet, read three letters at a time — sixty-four possible "words." Bacteria, oak trees, blue whales, you. But why three? Why not two, or four? For sixty years the polite scientific answer has been a shrug: "lucky accident, life got stuck with it."
Our first paper says the shrug is wrong. Feed the plain mathematics of sending a message through noise — Claude Shannon's 1948 masterpiece — the raw facts of chemistry, and it hands you "three" with almost rude confidence. Two-letter words are too clumsy to carry the load; four-letter words waste effort on distinctions the smudgy machinery can't reliably make. Three is Goldilocks, and three letters from a four-letter alphabet is sixty-four. (We'll be honest here, because we've learned to: we once claimed a second famous piece of math independently proved the same thing. It doesn't, quite — it provides a solid alibi, not a second conviction. One derivation plus a good alibi. We stopped overselling it.) And the answer barely budges when we crank the noise up and down across eight factors of ten. It's not a fragile peak. It's a wide, flat valley evolution could hardly have missed.
Chapter 2: A Bigger Dictionary Won't Help You Hear at a Party
If life's alphabet is pinned by math, what about AI? Surely a bigger vocabulary makes a smarter machine? We tested that on 1,749 different AIs. The verdict: vocabulary size predicts a machine's smarts about as well as menu length predicts a restaurant's food. Which is to say, not at all — it explains less than one percent. The bottleneck was never the words. It's the listener. At a loud party, a fatter dictionary doesn't help you hear; the noise sets the limit, and the noise doesn't care how many words you know. Same finding as the genetic code, now in silicon: the receiver, not the vocabulary, sets the speed.
Chapter 3: The Number That Keeps Showing Up Everywhere
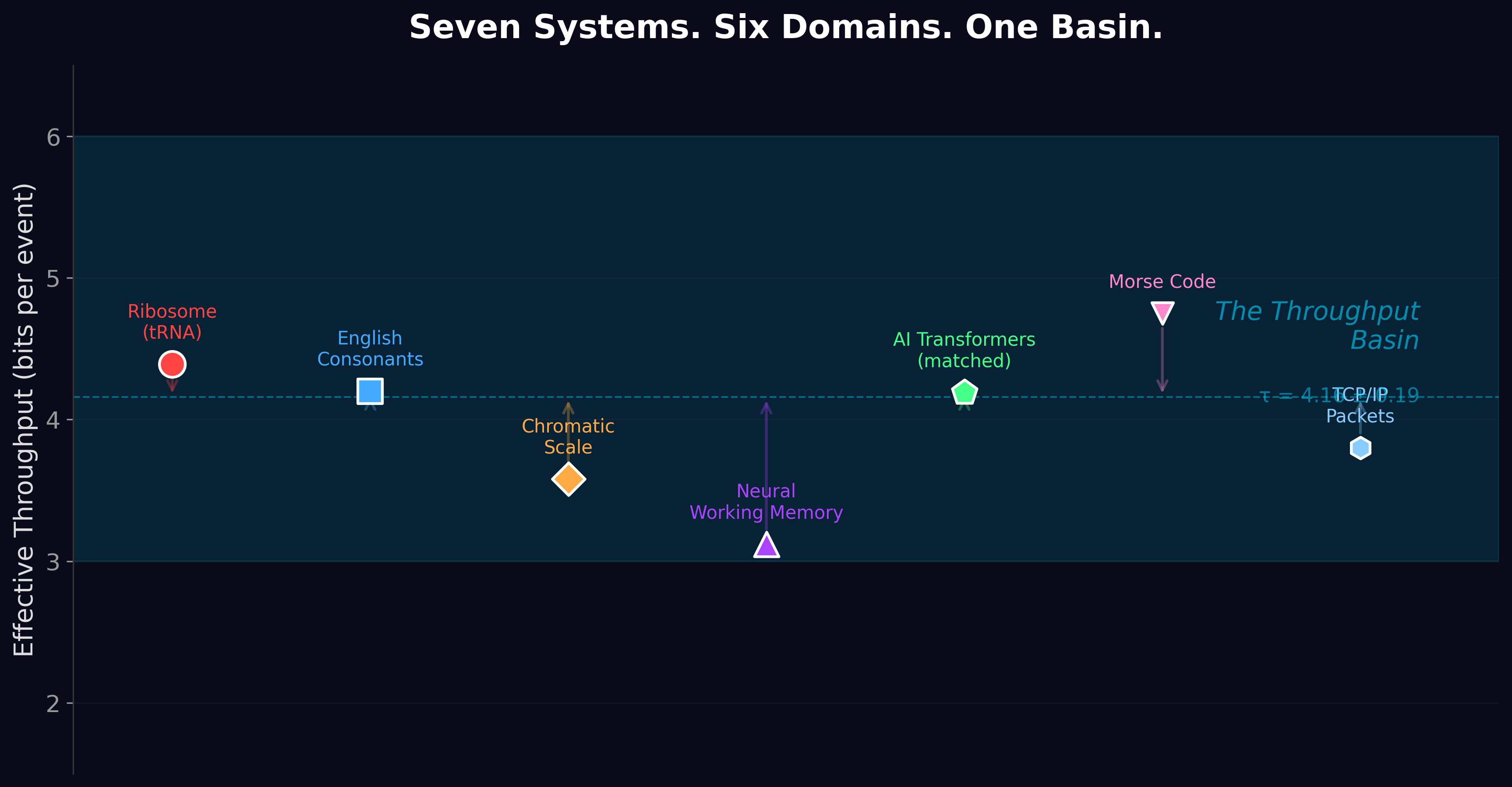
Two data points isn't a pattern — it's a Tuesday. So we went and counted thirty-one different one-thing-at-a-time systems across six unrelated worlds: genes, speech sounds, musical notes, working memory, telegraph codes, and AI. Almost every one landed in the same narrow band — a couple to six bits per step, most of them crowded around four. The ribosome, your ears (about 3.9 bits for consonants), the piano, your short-term memory, Morse code, the machines — all piling into the same little room like guests at a party gravitating to the kitchen. Run the numbers and a clustering this tight is hard to write off as chance — though, in full honesty, some of that punch leans on the AI systems in the pile.
Then the showstopper. We built a tiny digital Eden — imaginary critters free to evolve their own alphabets and error rates, fed zero biology. They clawed their way to an alphabet of about twenty symbols. One version landed on 19.76 — within six percent of life's actual twenty-one — with a sloppiness in the same ballpark as real cells, starting from nothing but arithmetic. A computer that had never heard of DNA reinvented the genetic code's front porch over a lunch break.
Chapter 4: Calling the Ribosome's Shot to Three Decimal Places
Patterns are nice; predictions are science. In our fourth paper we took four numbers other scientists had measured — in other labs, for other reasons — stirred them together with zero fudge factors, and predicted the ribosome's information throughput: 4.387 bits. Then we looked at what it actually does: 4.390. A miss of three-thousandths of a bit. That's not "the right ballpark." That's naming the year on the coin before it lands.
How good is the ribosome, then? At the job of extracting information, essentially flawless — it pulls nearly every drop its alphabet can carry, pressed right up against the information ceiling after billions of years of tuning. (One honest footnote, because it matters and we corrected ourselves on it: being a genius with information is not the same as being thrifty with energy. The ribosome still burns far more fuel than the bare physical minimum. Brilliant poet, slightly thirsty car. Both true.)
Chapter 5: Why Life Stopped at 20 Letters but AI Didn't
Four papers told us that everything lands at a few bits. The fifth finally cracked open why there — and the answer is the cost of telling things apart. Think of it as a bouncer problem. For life, every new kind of amino acid needs its own molecular bouncer, trained to tell it from all the others — and those pairwise checks balloon ruinously fast. So biology faces a real sweet spot: weigh what you gain against what the bouncers cost, and for a cell's brutal security bills, the books bottom out right around twenty symbols. That's why life stopped near twenty-one — not because twenty is a cosmic constant, but because that's where the economics quit paying off given what bouncers cost a cell.
Silicon found the cheat code. An AI doesn't hire a bouncer per word — it runs one giant shared ledger where adding a word is nearly free. We measured it: biology's costs balloon as it grows; silicon's costs grow gentler and gentler. So both have a sweet spot — they just sit in wildly different places. Expensive bouncers shove biology down into the cramped few-bit basin; a cheap ledger lets silicon float way up to a giant vocabulary. The basin, then, was never a universal law of the cosmos. It's the law of the expensive doorman. Biology has expensive doormen. Silicon has a spreadsheet.
We also went looking for the fingerprint in body heat: if telling symbols apart costs more when it's hotter, creatures in hot places should economize. Across twenty-nine organisms from near-freezing to near-boiling, the hotter ones did use leaner alphabets. We flag this ourselves as a promising clue, not a closed case — the controls are thin and it needs confirming. Heat appears to tax information. Probably.
The Twist: The Wall Was a Mirror
Now the plot turn that reorganized everything. That AI number — a few bits per step — we'd assumed was a wall built into the machines. Paper 7 proved us wrong. We built text with double the usual richness and fed it to the same AI. It didn't stop at the old number — it climbed, tracking its richer diet exactly, at every size we tried. The machine had never been hitting a wall. It was a mirror, faithfully reflecting how much genuine surprise was in the words we fed it. Ordinary language is gloriously repetitive, and after you subtract everything a good reader can already guess, a few bits of real surprise is about what's left. We'd spent six papers measuring the water and calling it the bucket.
That same paper caught us in an embarrassing measuring mistake, which we published loudly: one of our favorite numbers turned out to depend on how we chopped text into chunks rather than on anything real — the yardstick itself was partly an illusion. We fixed it, in daylight, and told you exactly how it bit our own earlier work. That's the house rule here: the attempt to kill an idea arrives holding hands with the idea.
Chapters 8 & 9: Into the Eye, the Ear, and the Chip
If the limit lives in the data, then different data should fill to different lines. Paper 8 checked, feeding machines pictures and sounds instead of words — and sure enough, each sense has its own waterline (pictures higher than words, speech higher than pictures), all obeying the same simple rule: what you carry equals what's there, minus what you can cleverly predict away. And we published the experiment that blew up in our faces right beside the one that worked.
Finally, Paper 9 went down to the actual switches on a computer chip to prove the "bits" were real, physical things. There's a notorious cliff where shrinking an AI too far turns it to gibberish — everyone assumed a hard four-bit floor. We showed it's not about how many bits but where you spend them. The very same budget, placed wisely versus foolishly, is the difference between Shakespeare and static. Fix the budgeting and the cliff moves — a fact worth real money to chip designers.
So What's It All Good For?
Plenty. For AI builders: stop pouring money into vocabulary, spend it on the listener. Stop shipping a single letter in a moving truck — a few bits of signal don't need sixteen bits of precision. For the search for alien life: any creature anywhere that reads information single-file under noise would face the same math, and land in the same few-bit neighborhood — its chemistry unrecognizable, its information architecture eerily familiar. And for physics, the whole thing rhymes with the Carnot limit for engines: not a fact about any one machine, but a fence around what any machine can do.
The Honest Ledger
We've made falsifiable bets that could still lose. The heat-tax prediction has early support but needs sterner tests. The expanded-genetic-code prediction awaits lab data. The whole "AI inherited the limit from us" story awaits a decisive control. Any of them could fail — and that's the point. Science doesn't advance by building ideas too slippery to be wrong. It advances by making bets sharp enough to lose, and then honestly checking. We've tried to show you every stumble as plainly as every triumph, because the stumbles aren't the embarrassing footnotes. They're the job.
The ribosome has been running at nature's optimum for nearly four billion years. Human engineering has had about seventy. And here we are, converging on the same quiet point from opposite directions, out of different materials, for different reasons — because the math keeps insisting there's nowhere else to go. The universe has a speed limit on thought, and we've been mapping it.
And that's only Act One. Partway through, we noticed information and energy are braided together so tightly that the same lens might reach somewhere wilder — the physics of gravity, entropy, and black holes themselves. That hunch became a whole second act, out among the collapsing stars, and it's every bit as strange as it sounds. But that's a story that begins over here.
The papers referenced in this article are available on Zenodo. All code, data, and experiment protocols are published at github.com/Windstorm-Institute. The Windstorm Institute is headquartered in Fort Ann, New York.
For correspondence: Grant Whitmer — [email protected]
Comments & questions
Comments are powered by GitHub Discussions. Sign in with your GitHub account below, or browse all discussions on GitHub. No GitHub account? It takes 30 seconds to make one — or email Grant directly if you'd rather skip it.